人脸肖像编辑指基于一幅给定的人脸图像,对人脸的属性或组成进行编辑,并且生成的图像看起来真实自然,其在影视制作、照片处理和交互式娱乐等方面具有广阔应用前景。针对这个问题,媒体深度伪造与反伪造创新团队成员博士生邓琪瑶、李琦副研究员、孙哲南研究员等人提出了一种从参考图像学习目标人脸组成形状的人脸组成编辑算法(r-face)。该方法创新性地提出了多样化且可控的人脸组成编辑方法,并较好地保留原始图像的姿势、肤色等风格特征,与传统算法及商业ps算法等相比有明显视觉效果提升。相关成果论文《reference guided face component editing》获得6位专业审稿人一致肯定,被ijcai 2020录用。
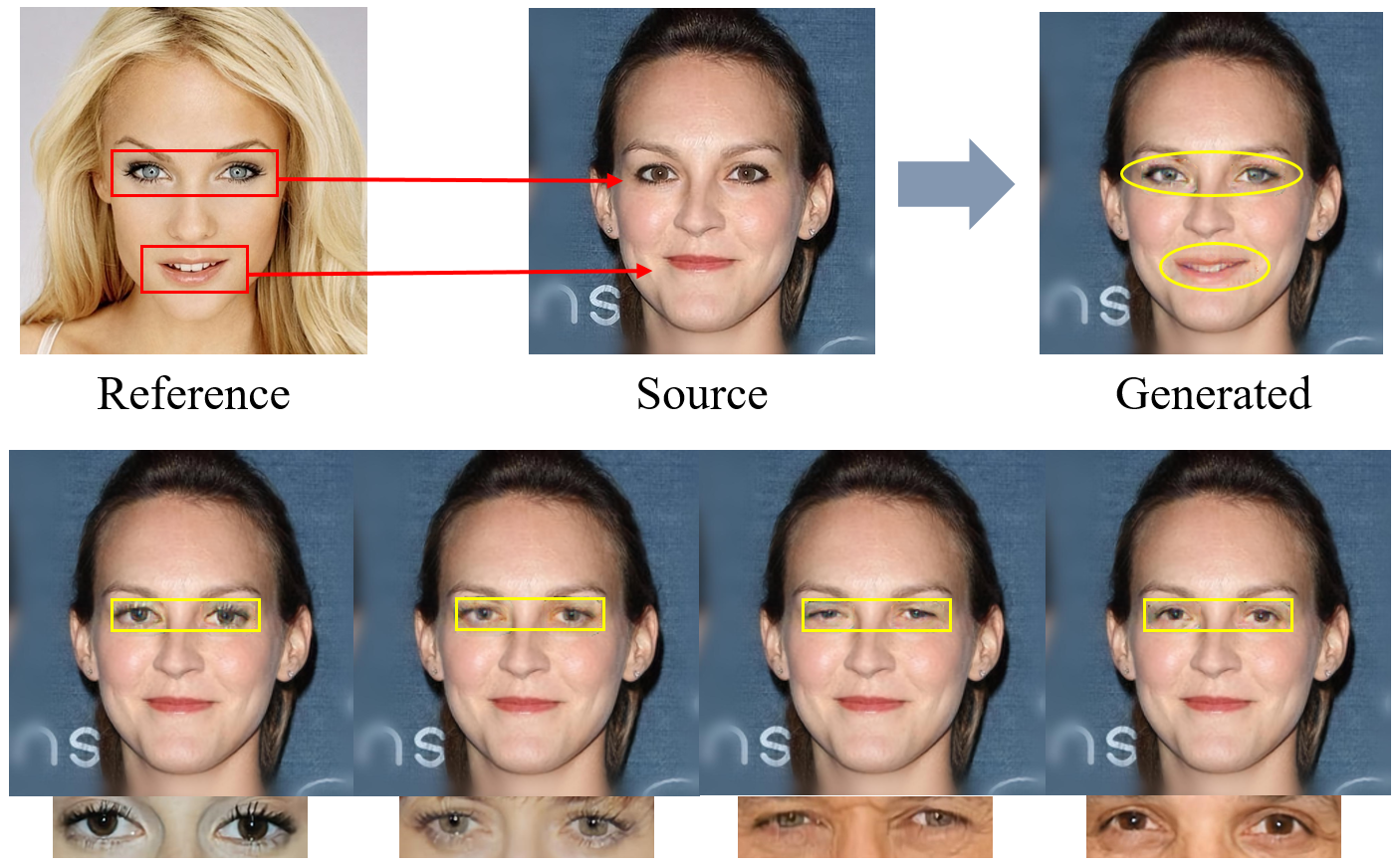
图1.基于参考图像引导的人脸组成编辑示意图
近年来随着生成对抗网络[1]的发展,人脸肖像编辑已取得巨大进步。目前,主流的人脸肖像编辑方法聚焦于两类:基于标签条件的方法和基于几何指导的方法。基于标签条件的方法[2-3]以预定义的属性标签为条件编辑人脸属性。然而,基于标签条件的方法以二值属性标签为条件,只适用于编辑外观纹理变化的显著属性(例如:发色、年老化和去除胡子等),难以实现抽象形状变化(例如:鹰钩鼻、丹凤眼等),缺乏控制高级语义人脸组成(例如:眼睛、鼻子和嘴等)形状的灵活性。为了能灵活编辑人脸组成的形状,基于几何指导的方法[4-5]提出利用手动编辑的中间表示(例如:关键点,分割图和轮廓草图等)实现具有明显拓扑形变的人脸组成编辑。然而,直接将如此精确的中间表示用作形状指导对用户而言并不友好,这种方式费时费力并且要求用户具备一定的绘画技能。
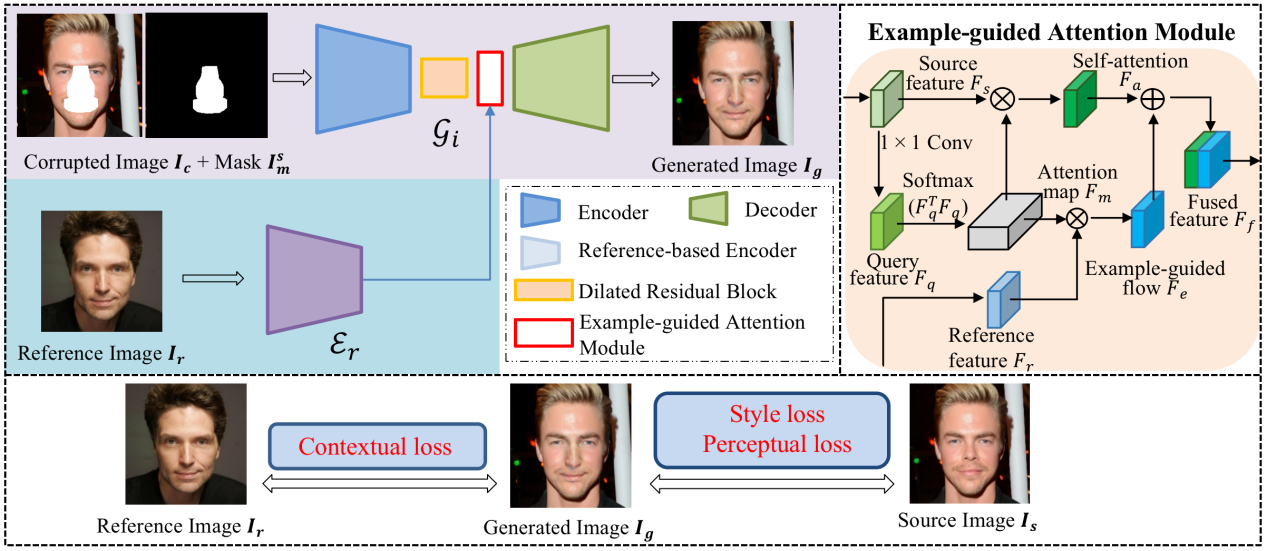
针对这个问题,团队提出了一种从参考图像中学习目标人脸组成形状的人脸组成编辑算法,以图像补全模型作为基本框架,以缺失目标人脸组成的图像作为输入,从参考图像中学习相应的人脸组成形状信息补全缺失区域,实现对人脸组成的语义形状编辑。相比现有的基于参考图像方法[6],该算法要求相同身份的参考图像,由于这些参考图像可以是任意身份,因此进一步提高了生成图像的多样性。为了监督所提出的模型,团队选择采用contextual 损失约束生成图像和参考图像之间目标人脸组成形状的相似性,同时采用style损失和perceptual损失保持原始图像和生成图像之间姿势、肤色等风格特征的相似性,整体模型框架如图2所示。
除此以外,为了使框架聚焦于目标人脸组成,该方法设计了一个示例指导的注意力模块(example-guided attention module),以融合原始图像的注意力特征和从参考图像中提取的目标人脸组成特征,进一步增强了模型的生成效果。总的来说,所提出框架打破了现有方法的2种限制:1)形状限制, 通过不同的参考图像灵活地控制高级语义人脸组成的各种形状; 2)中间表示限制,不需要手动编辑精确的蒙版或草图就可以实现显著的几何变化。
图2.模型框架示意图
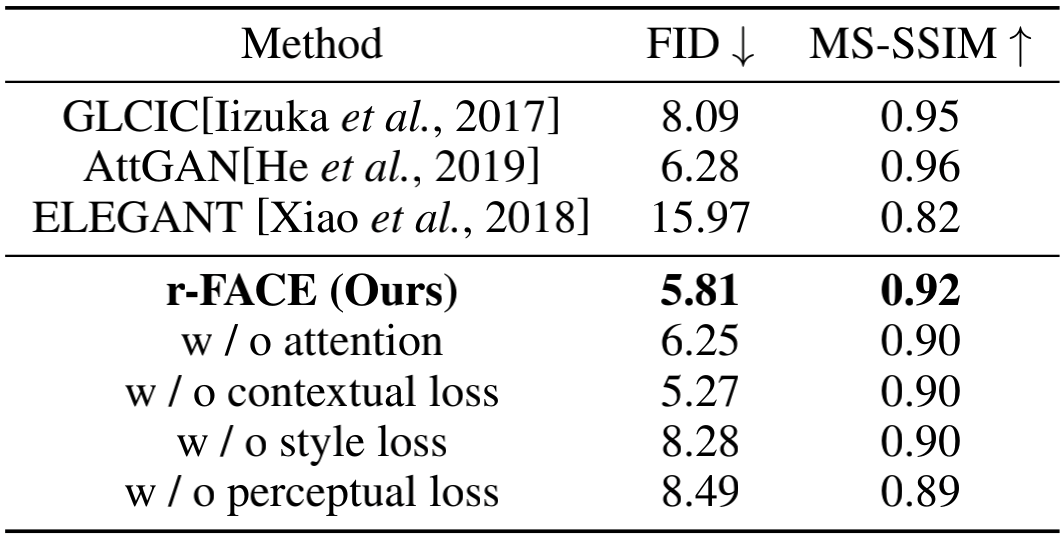
团队提出的方法在常用人脸属性数据集celeba-hq上进行了定性和定量分析。实验结果表明,该方法能够生成高质量和多样化的人脸,并可以实现显著语义形状变化的人脸组成编辑。这也是团队在媒体深度伪造领域上的又一进展。
图3.不同方法比较结果:(c)复制-粘贴,(d)attgan,(e)elegant,(f)adobe photoshop和(g)r-face。(a)和(b)分别表示输入图像和参考图像。
图4.混合人脸组成编辑样例
表1.celeba-hq数据集定量比较结果
参考文献:
[1] ian goodfellow, jean pouget-abadie, mehdi mirza, bing xu, david warde-farley, sherjil ozair, aaron courville, and yoshua bengio. generative adversarial nets. in neurips, pages 2672–2680, 2014.
[2] yunjey choi, minje choi, munyoung kim, jung-woo ha, sunghun kim, and jaegul choo. stargan: unified generative adversarial networks for multi-domain image-to-image translation. in cvpr, pages 8789–8797, 2018.
[3] zhenliang he, wangmeng zuo, meina kan, shiguang shan, and xilin chen. attgan: facial attribute editing by only changing what you want. ieee tip, 2019.
[4] shuyang gu, jianmin bao, hao yang, dong chen, fang wen, and lu yuan. maskguided portrait editing with conditional gans. in cvpr, pages 3436–3445, 2019.
[5] youngjoo jo and jongyoul park. sc-fegan: face editing generative adversarial network with user’s sketch and color. in iccv, october 2019.
[6] brian dolhansky and cristian canton ferrer. eye in-painting with exemplar generative adversarial networks. in cvpr, pages 7902–7911, 2018.
|